What is Data Caching?
Xano provides a data caching service, powered by Redis, that allows you to temporarily store data in memory for high-performance data retrieval and storage purposes. This is great for storing temporary data that needs to be quickly generated and accessed for a period of time.
If you are retrieving data from a database or an external API, for example, that you know never, or very infrequently, changes, using data caching can be incredibly valuable.
How long can I store data in the Data Cache?
Through the cache functions you use, you can manually set how long data gets stored, or you can expect it to naturally get overwritten once it reaches the 100MB limit.
NoteAs mentioned above, Data Caching is temporary storage - so never store something that can’t be recovered - if permanent storage is required, then the database can and should be used.
Caching Functions
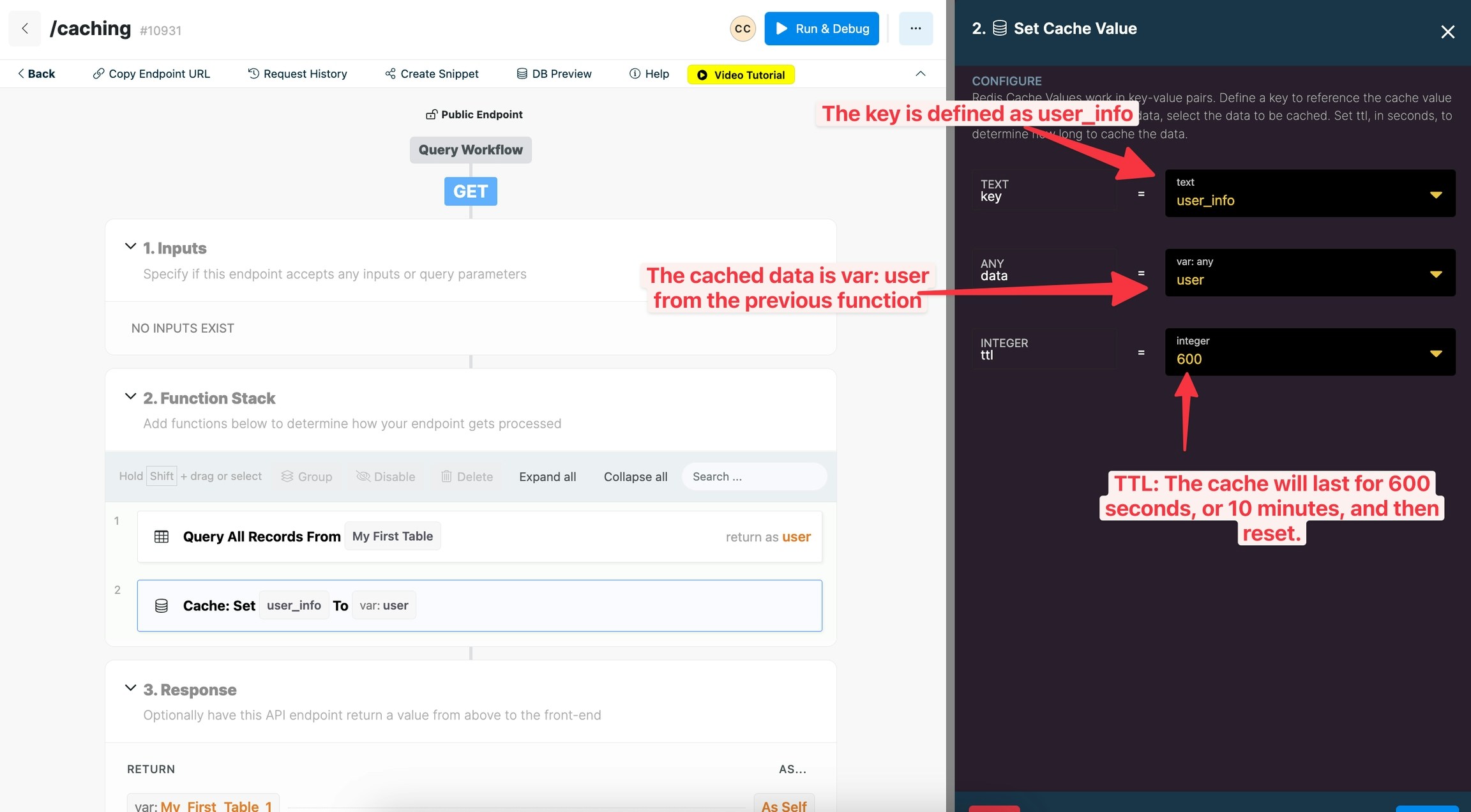
Set a Cache Value
Redis Cache Values work in key-value pairs. Set a Cache Value function allows you to define a key to reference the cache value in other cache functions. The data input is where you define the data you wish to be cached (the value of the pair). Ttl stands for time to live. Set this, in seconds, to determine how long to cache the data for.
Key: define a key name to reference the cache value by.
Data: select the value that you wish to cache. This will often be a variable containing data.
TTL: define how long, in seconds, for the cache to last. After this time expires, the query will run normally again and reset the data cache value for the specified time. Set this equal to 0 never reset the cache value.
Redis is extremely sensitive to data variation, so you may find it useful to store JSON objects as text strings for easier use of additional caching functions, such as ‘removing from list’.
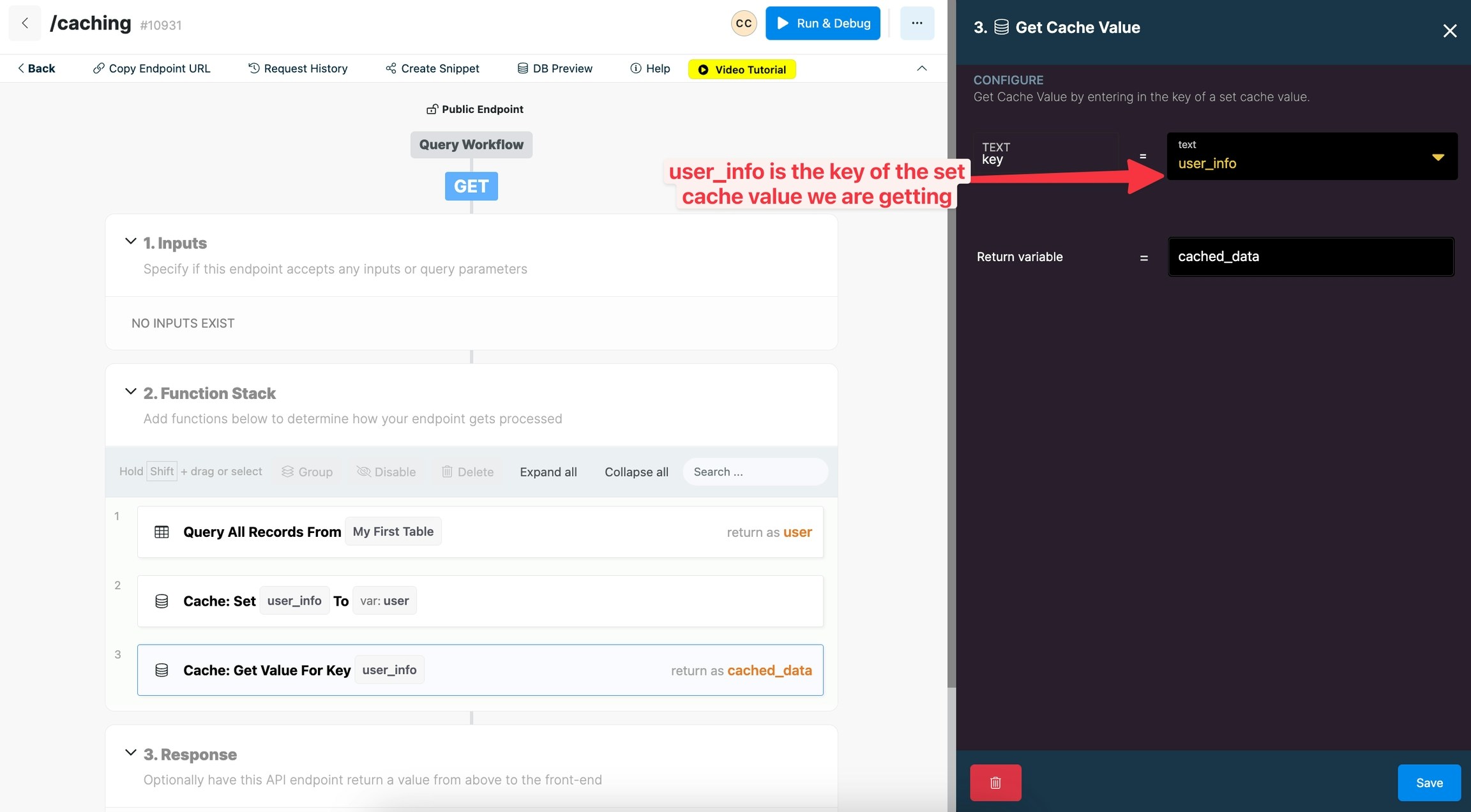
Get a Cache Value
Get a Cache Value allows you to retrieve a cache value based on the defined key of a set cache value. Get a Cache Value function also outputs a variable so that you can use the data from the cache value in other functions or in the response.
Key: enter in the key of a set cache value that you wish to retrieve.
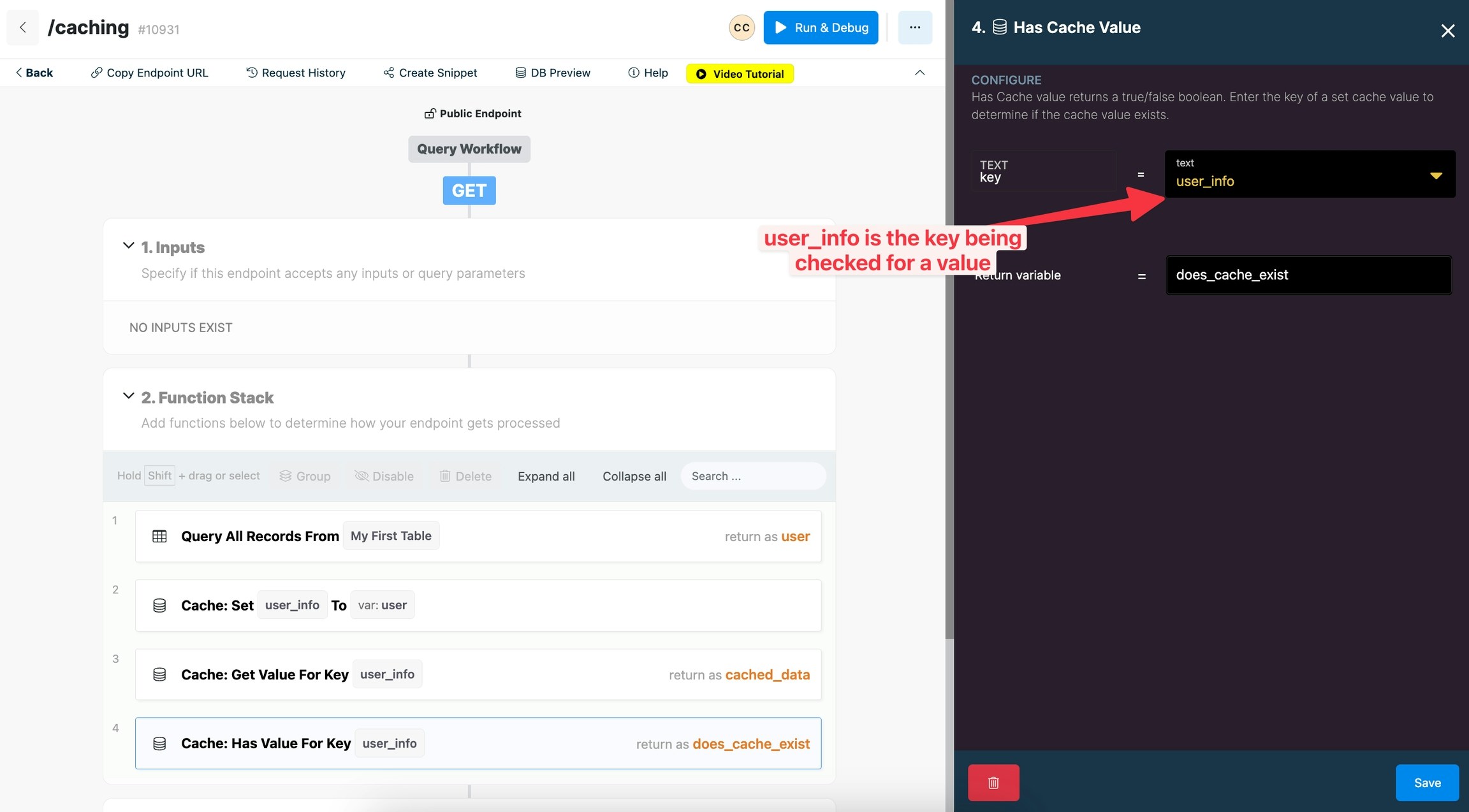
Has a Cache Value
Has a Cache Value allows you to determine whether or not a cache value exists based on the key. This function will return a boolean of true or false as a variable depending on if the cache value exists.
Key: enter a key to find if a cache value exists.
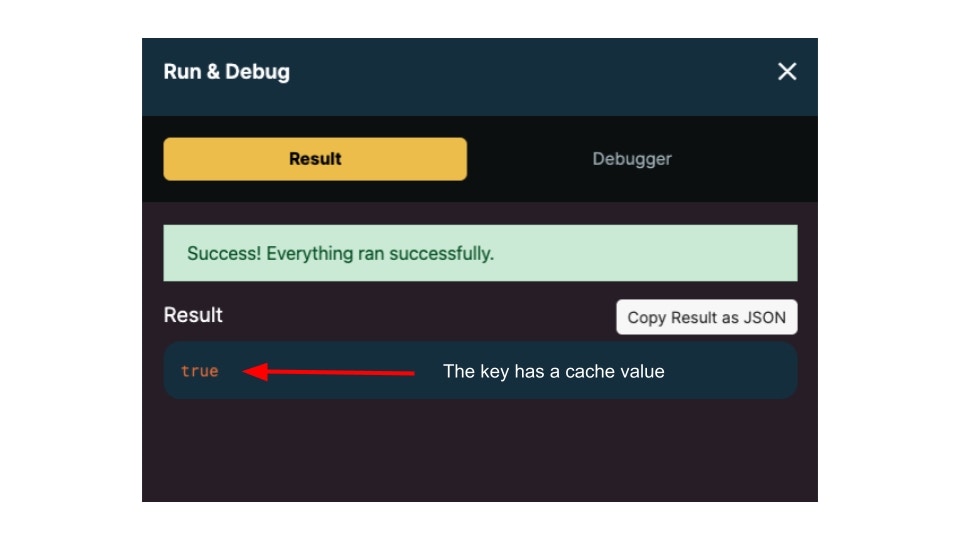
The return variable result will look like this:
Because the key “user_info” has a cache value, the return variable is true.
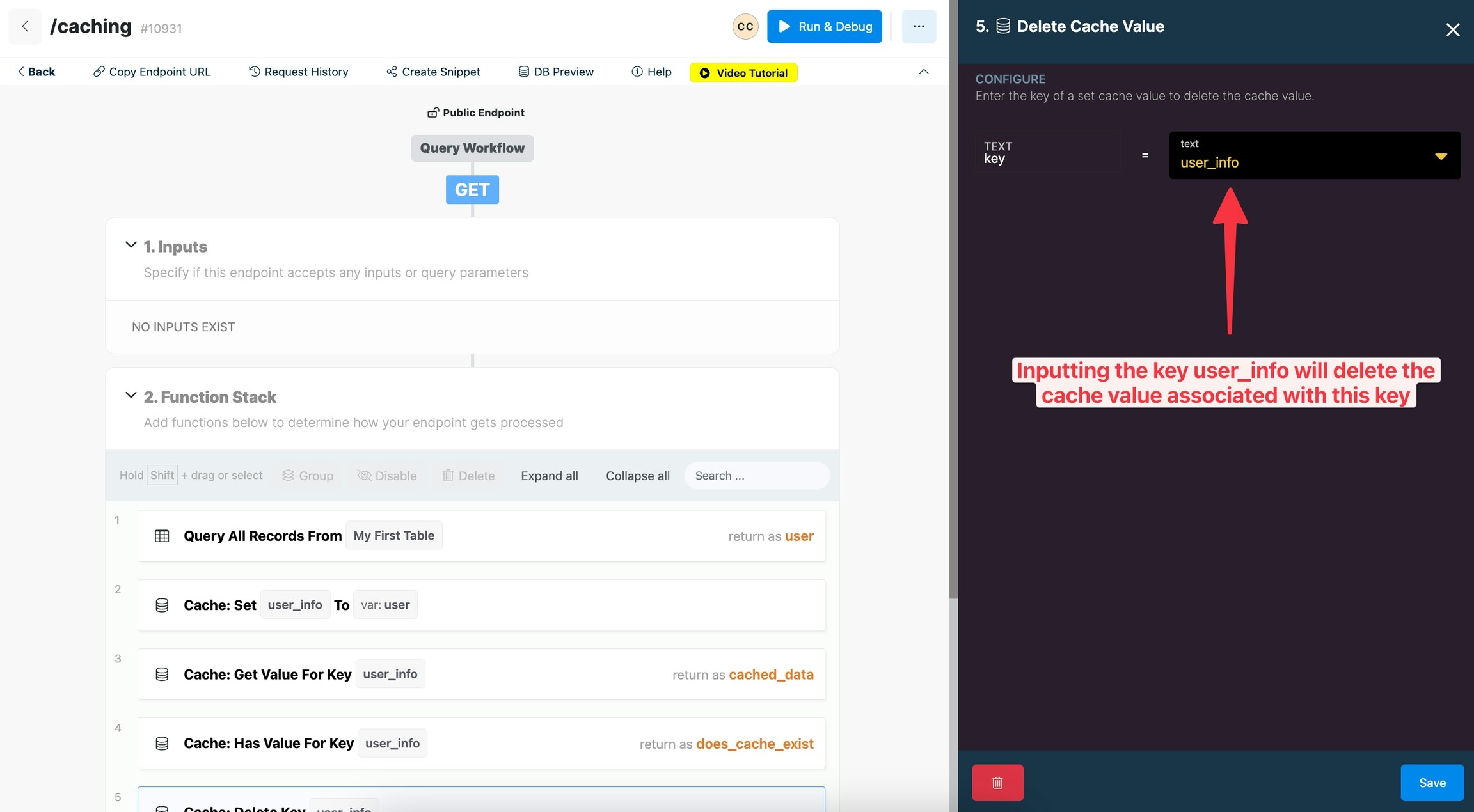
Delete Cache Value
Delete cache value will delete a cache value based on the key of the cache value.
Key: enter in the key of a set cache value in order to delete it.
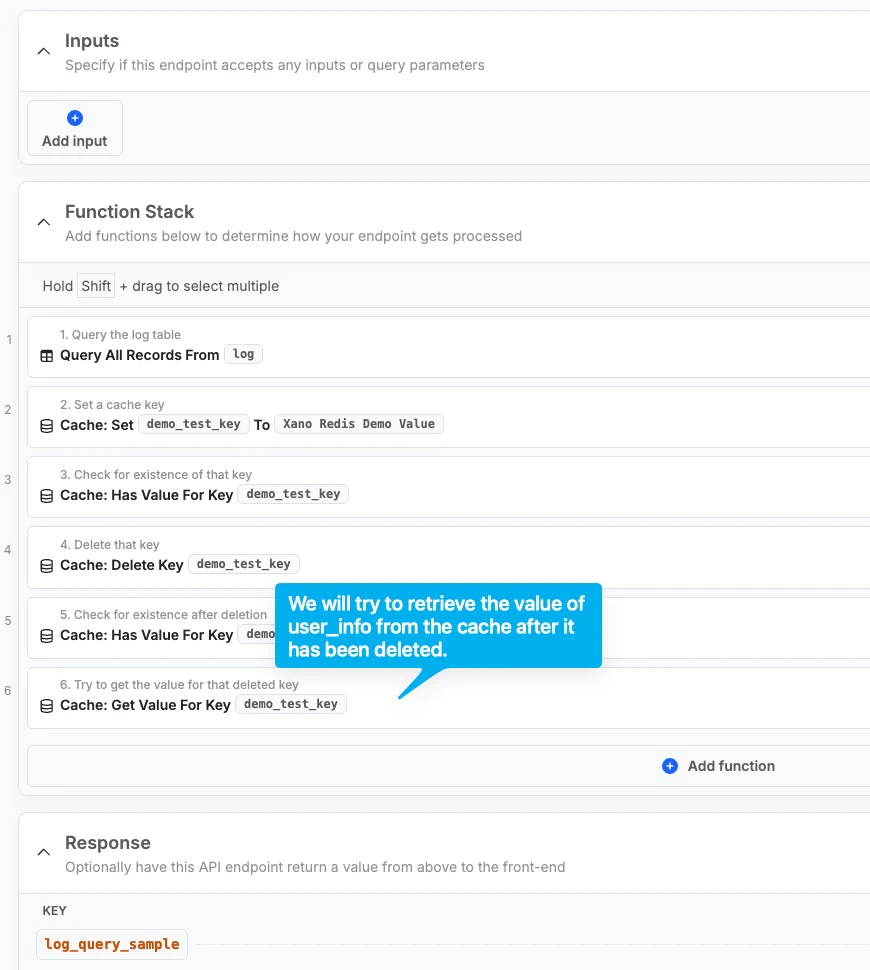
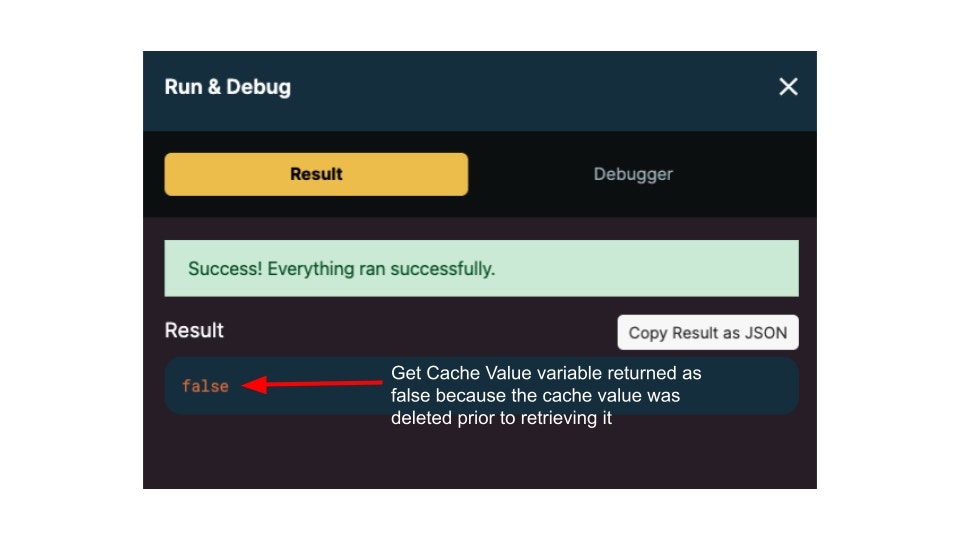
If we try to Get Cache Value for the same key after it is deleted, the response will come back as false.
In this example, we are doing a Get Cache Value for the same key that is being deleted in the prior step. We will try to return the return variable of the Get Cache Value.
The Get Cache Value returned a result of false because the cache value was already deleted.
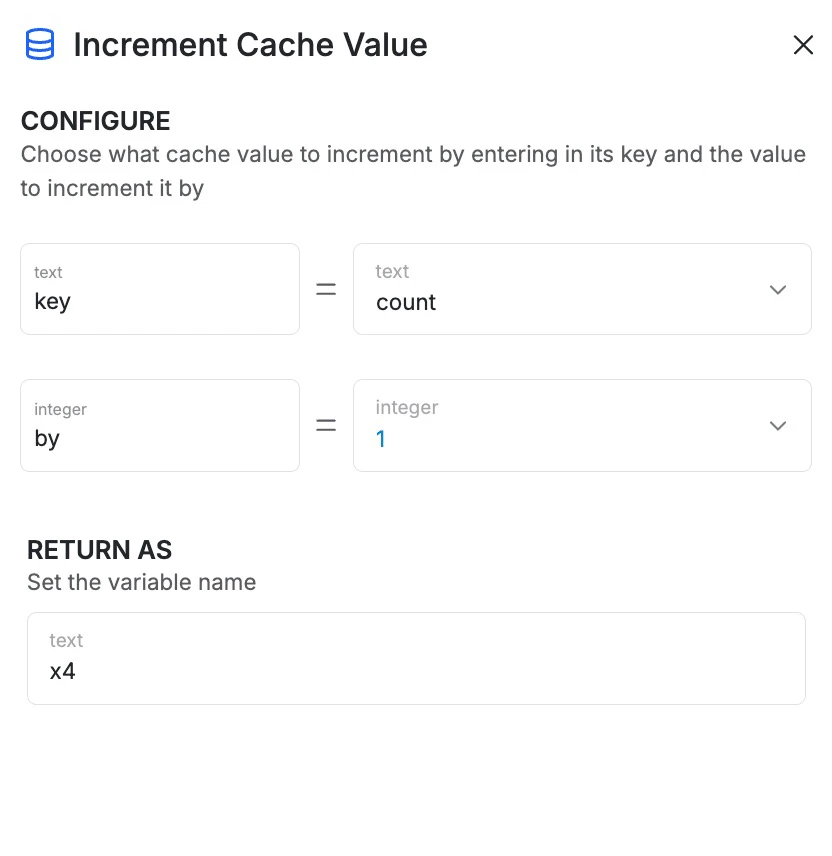
Increment Cache Value
Increment Cache Value allows you create an Incremental Cache Value by choosing a key and choosing the value to increment by. The incremented value is returned in a variable so you can perform logic based on what the count is.
Key: set a key name.
By: choose the value to increment by.
Increment Cache Value can act as a lightweight counter. The incremental values are stored on temporary memory, so keep in mind, if the server were to ever restart then the count would be reset.
Use case examples include a promotion where something is available or accessible for the first 100 users. Or perhaps, the 100th user wins the promotion.
Decrement Cache Value
Decrement Cache Value allows you to decrement a cache value by choosing a key and a value to decrement it by. The decremented cache value is returned in a variable so you can perform additional logic based on its value.
Key: create a key name for the decrement cache value.
By: choose the value to decrement by.
Decrement cache value is similar to increment cache value but it decreases the value. You can also use this as a counter stored on temporary memory.
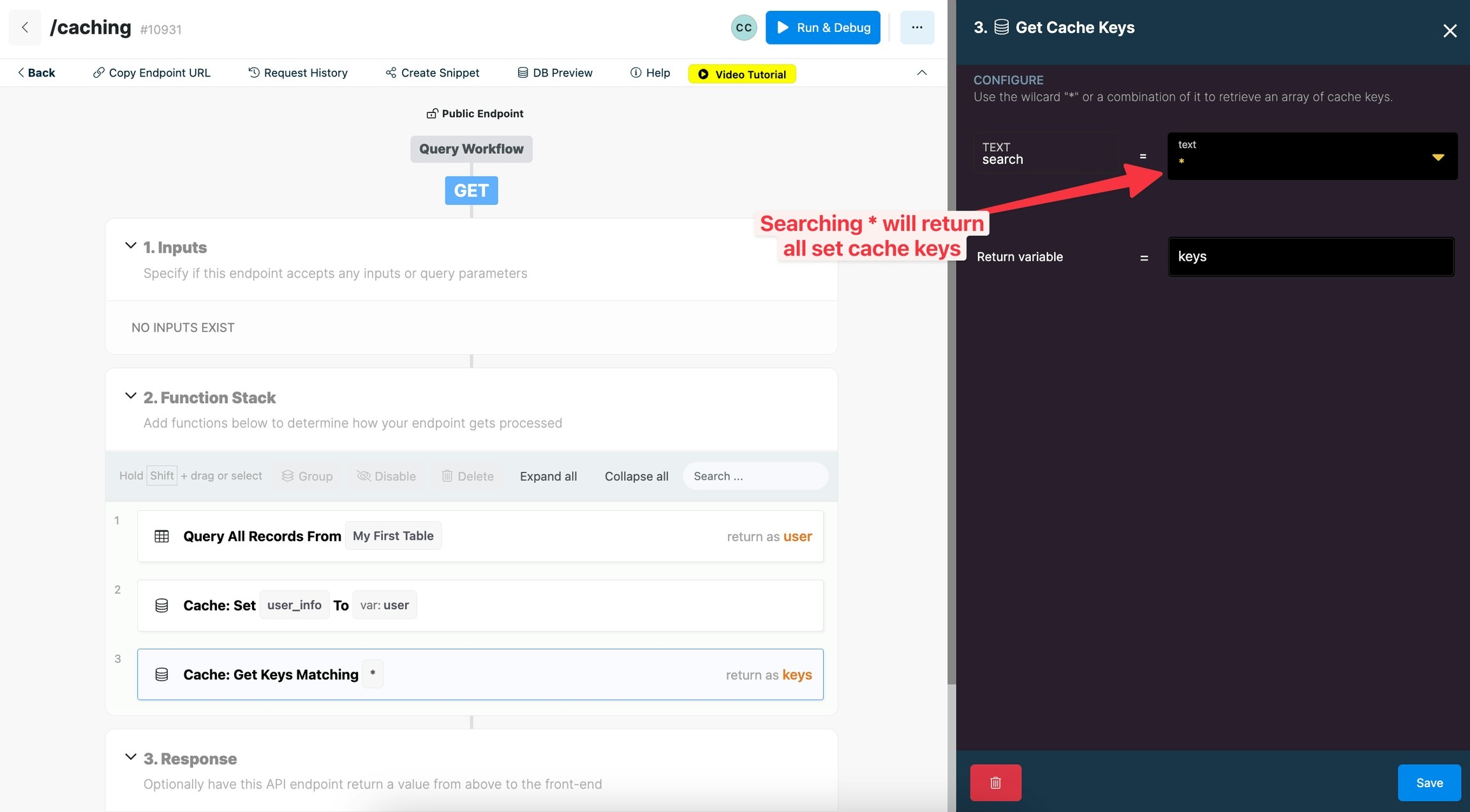
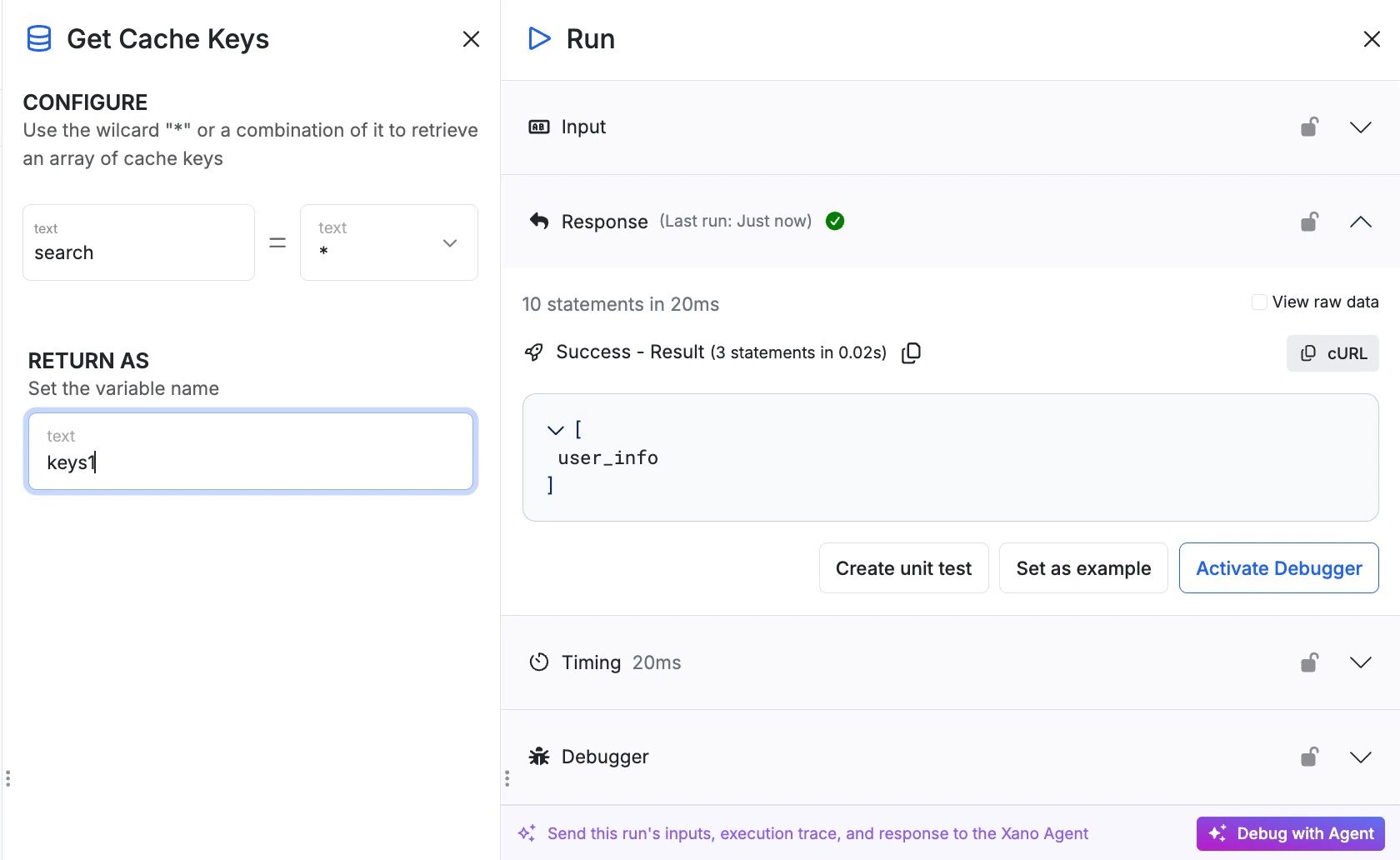
Get Cache Keys
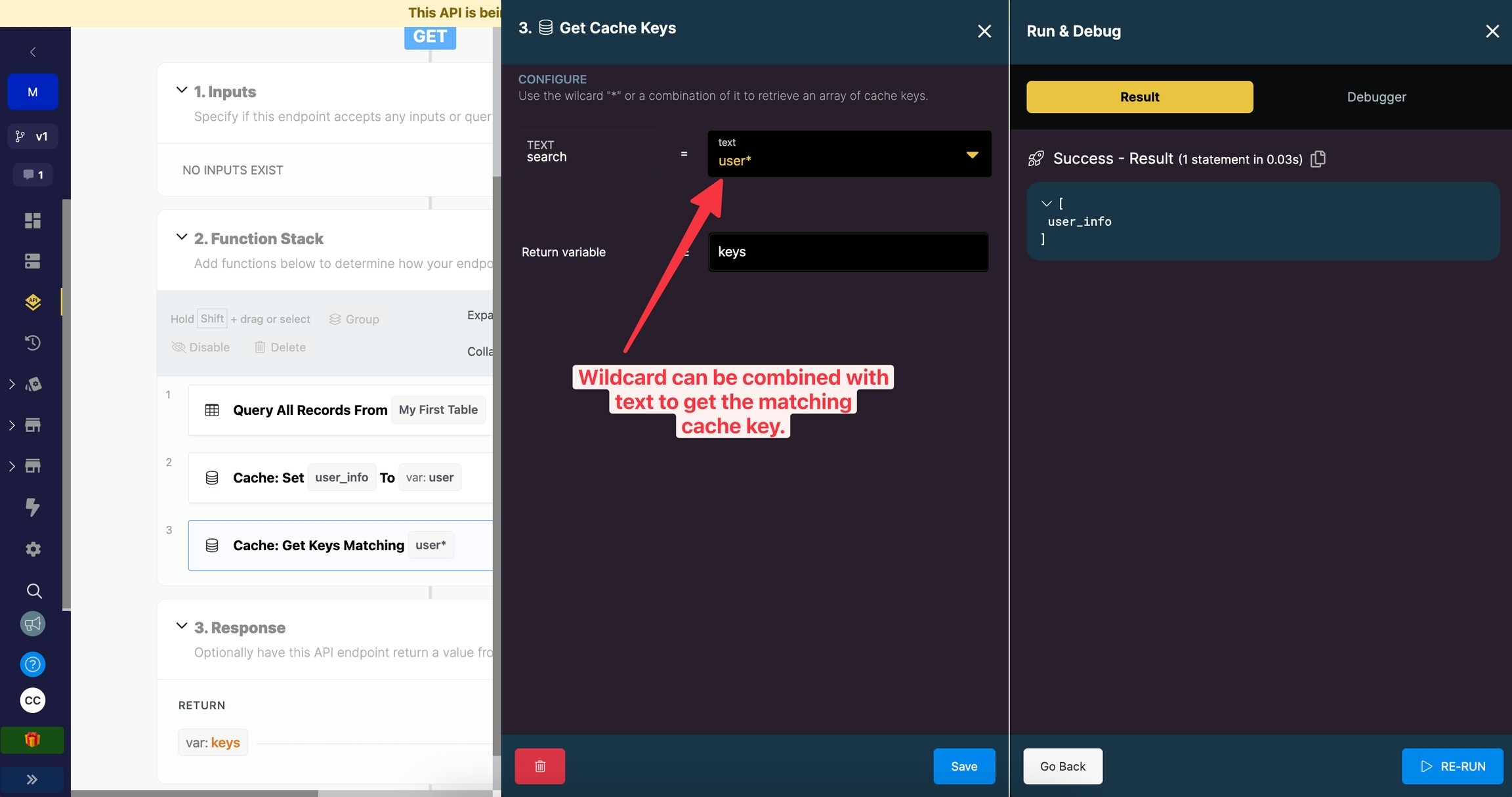
Get Cache Keys allows you to retrieve cache keys that match a searched value. You can use ”*” as a wildcard to search. Only putting in ”*” will grab all keys but you can combine it with with text string to narrow your search.
Search: enter in they name of the keys you are searching for. Use ”*” as a wildcard.
Here’s an example of combining the wildcard ”*” with text to retrieve cache key.
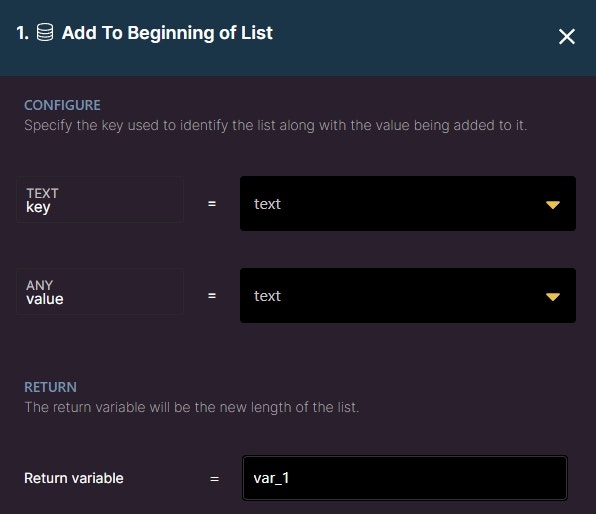
Add to Beginning of List
Add to Beginning of List allows you to insert a value at the start of the list stored at a key you specify.
Key: set a key name.
Value: the value to add to the beginning of the list.
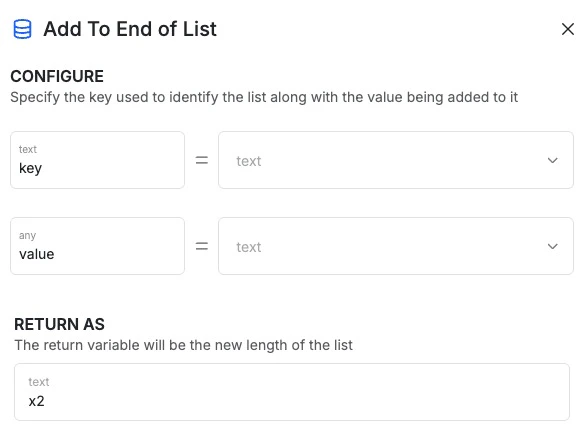
Add to End of List
Add to End of List allows you to insert a specified value at the tail end of the list, stored at the key you specify.
Key: set a key name.
Value: the value to add to the end of the list
Remove from Beginning of List
Allows you to remove the first element from a list stored at a key you specify.
Key: the key that you’d like to remove the value from
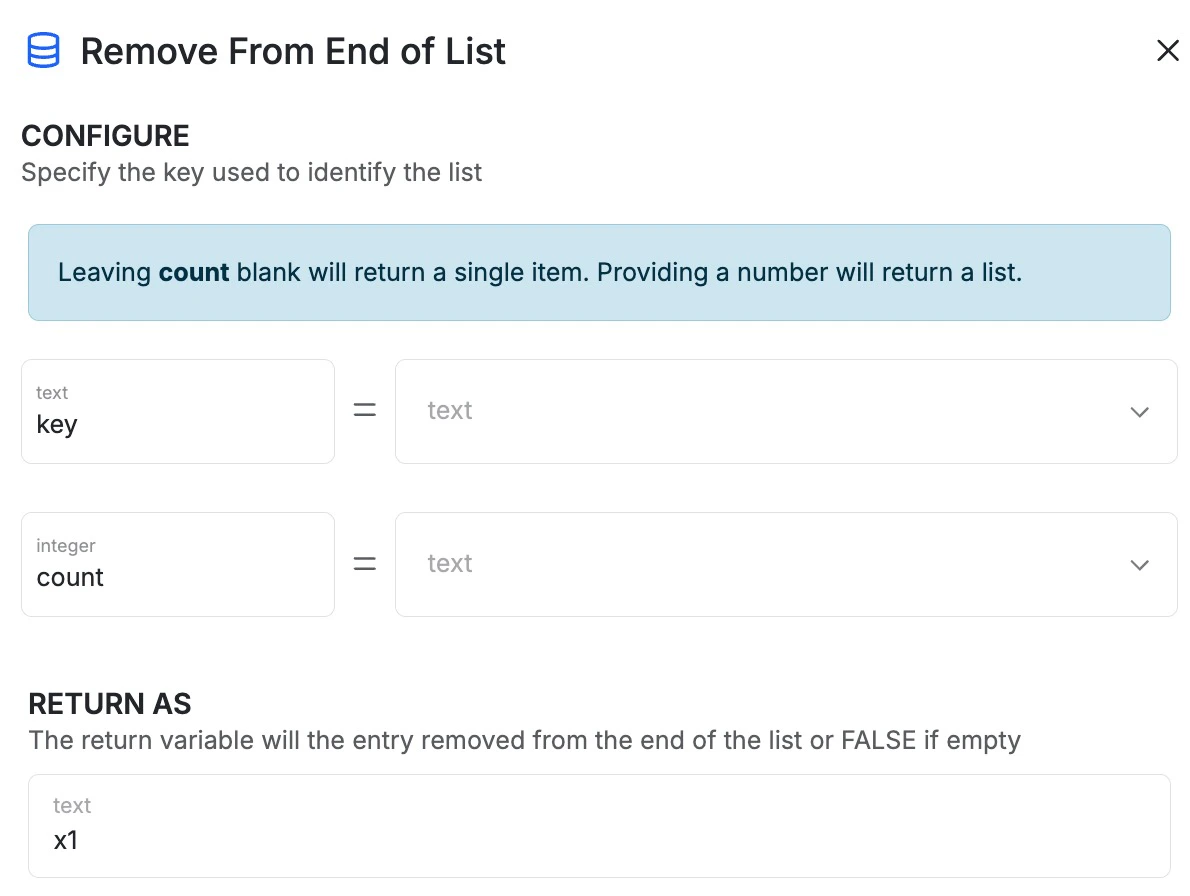
Remove from End of List
Allows you to remove the last element from a list stored at a key you specify.
Key: the key that you’d like to remove the value from
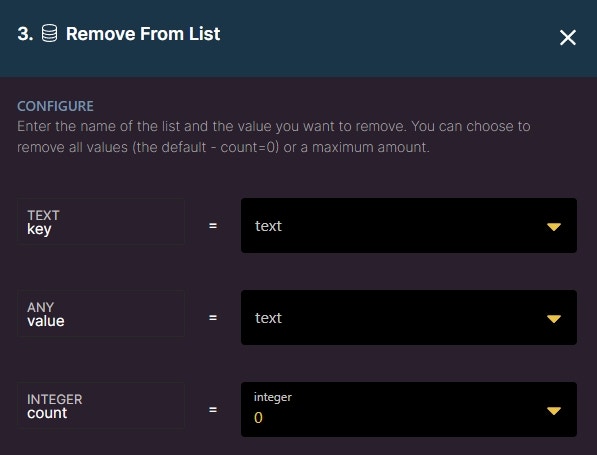
Remove from List
Allows you to remove a specified item from a list. You can choose to remove all specified values, or a maximum amount.
Key: the key that you’d like to remove the value from
Value: the value you would like to remove
Count: the amount of values you want to remove. The default (0) will remove all, or you can specify a maximum.
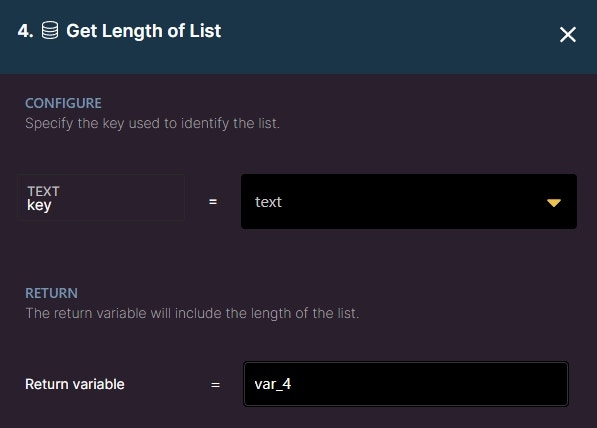
Get Length of List
Allows you to return the current length of a list as a variable.
Key: specifies the key you would like to reference
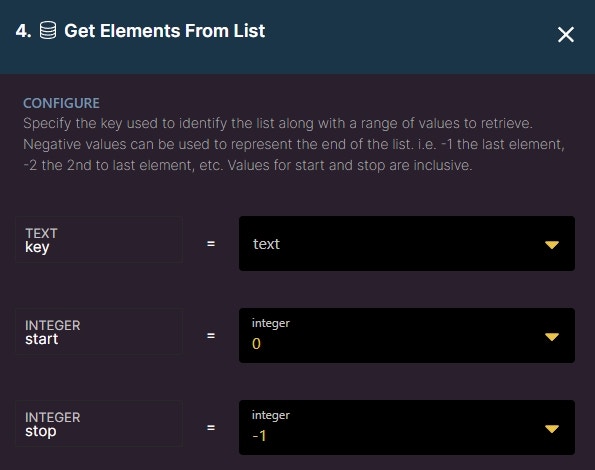
Get Elements from List
Allows you to retrieve a range of values from a list.
Key: specify which key you would like to reference.
Start: identifies the start of the elements you would like to retrieve.
Stop: identifies the end of the elements you would like to retrieve.
You can use negative values to represent the end of the list (ex. -1 is the last element, -2 is the second to last, and so on). The start and stop parameters are also inclusive. This means that the results you are given will include the elements at the positions you start and end with.
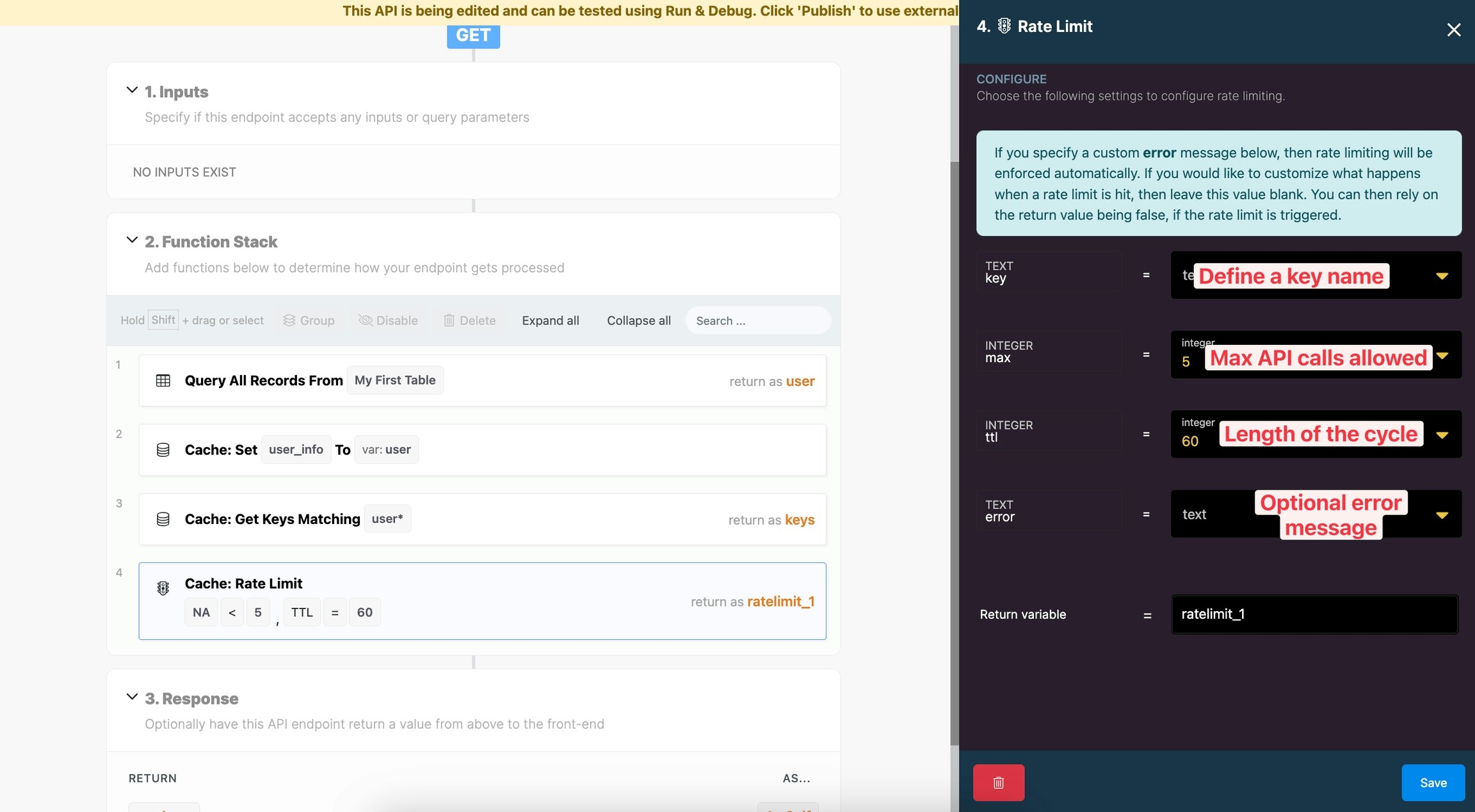
Rate Limit
Xano allows you to set rate limits on your queries so that you can limit the requests per given time period that an API endpoint can be called.
The Rate Limit function comes with a few settings for configuration.
Key: define a key for the rate limit.
Max: set the max amount of requests allowed in the given time or TTL.
TTL: set the time to live, in seconds, of each cycle.
Error: optionally include an error message. If you include an error message, when the Rate Limit is reached it will automatically throw an error and display this message. If you do not, the Rate Limit will output a boolean of false when the Rate Limit is reached. This can be used if you wish to create custom logic for what happens when the Rate Limit is reached.