Quick SummaryThrough Xano’s Microservice feature, you can deploy Ollama as a part of your Xano instance, enabling secure communication with an off-the-shelf or customizable LLM tailored specifically to your needs.
What is Ollama?
Ollama is a platform that enables seamless integration of large language models (LLMs) into various applications. It provides an environment where businesses can deploy pre-built or customized LLMs, facilitating secure and efficient communication tailored to specific business needs. This makes it easier for companies to leverage advanced AI technology without extensive in-house development, and without the concerns of sending data to a third-party AI provider. In addition, deploying Ollama as a part of your Xano instance can be a significant cost-saving measure in comparison to leveraging a third party service.What can I do with Ollama + Xano?
Deploying Ollama as a microservice in Xano helps address a critical data privacy challenge when building AI-enabled applications that handle sensitive information. By processing data within your controlled infrastructure boundary rather than sending it to external AI providers, using Xano with microservices removes one significant barrier to developing secure applications that can still leverage the benefits of AI models.Getting Started
1
If you're not on an Enterprise or Custom plan, reach out to our team to get started.
2
Head to your instance settings, and select Microservices
3
Choose a model to deploy
You’ll want to know which model you’re deploying so we understand the resources that need to be allocated. Check out the resource linked below if you need help choosing a model.Choosing a Model
4
Add a persistent volume
A persistent volume is just a place that the microservice can store data that remains between restarts. Ollama will use this volume to store the model(s) that you’re working with.Name the volume 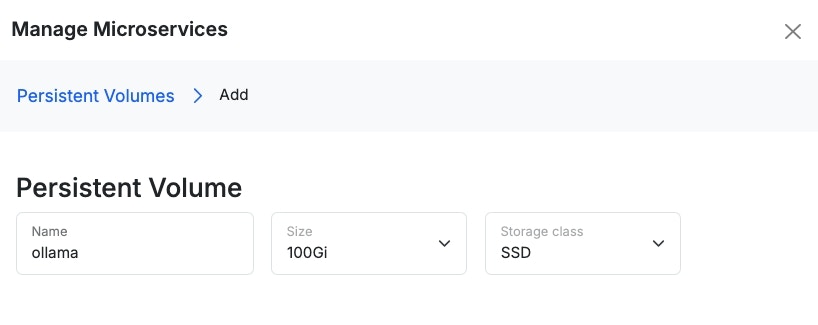
How much storage do I need?When browsing Ollama models, use the Size column for your chosen model to determine how large of a volume you should deploy. Make sure to add a little extra when creating your volume, just for some breathing room.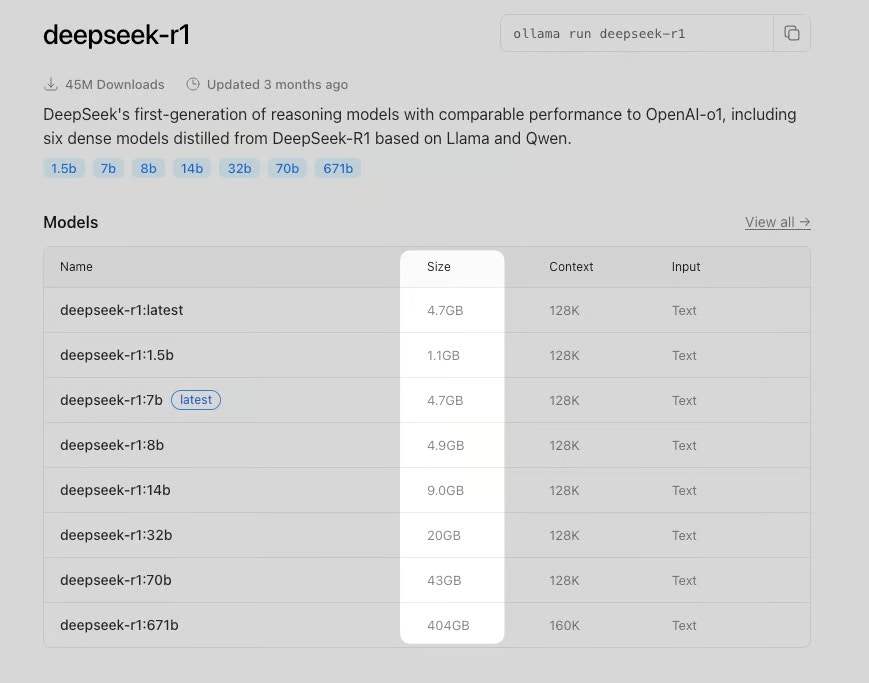
ollama, select the size, and choose SSD as the storage class. When you’re ready, click Add5
Add a deployment
Click Add under DeploymentsFill out the following information. For this example, we’ll be deploying the
phi3:mini model, which should work with the following example values.Click Add and then Update & Deploy
6
Deploy your chosen model
All interactions with Xano microservices are facilitated by the Microservice function, which is a REST API request to your chosen microservice.Use the cURL below to get started. Add a Microservice function to your function stack, and click Import cURLClick on the 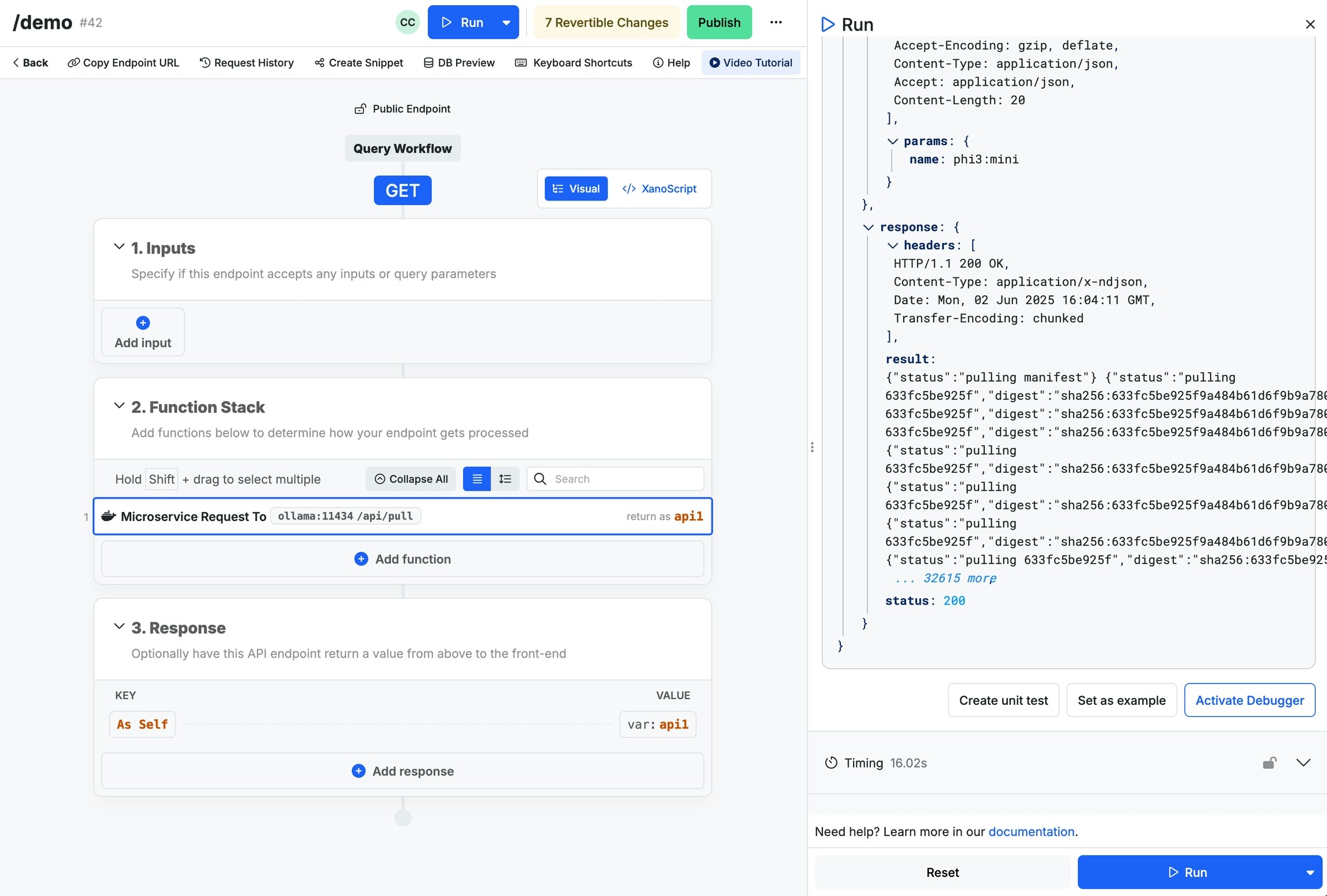
host dropdown and choose your deployment, likely called ollamaChange the timeout to a value that will allow you to monitor the deployment right inside of Xano. Below are some recommended values. You can also monitor the deployment via the logs of the microservice, available from your instance settings where you deployed the microservice earlier.Once the model has downloaded, you’ll be returned a 200 status response, as shown below. The model will be saved to your persistent storage volume, so you should only have to do this once.
7
Interact with your Ollama deployment
You’re ready to receive generations from your Ollama microservice. Here’s an example cURL command to get you started.The above command will return an output like the one shown below.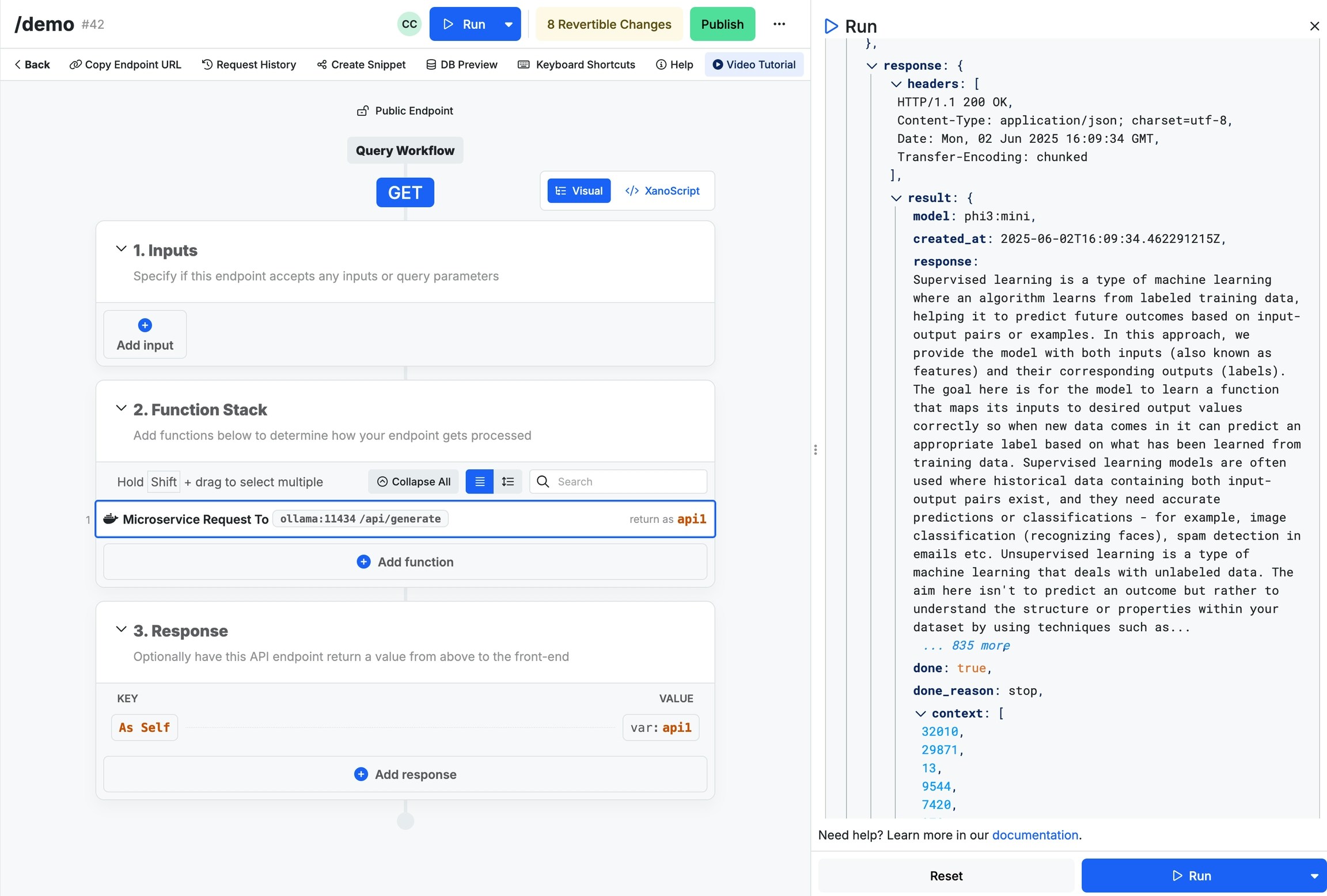
8
What's next?
Ollama offers a set of standard commands that can be issued via REST API endpoints. You can review them here, and use them as necessary inside of your function stacks.