What is an Index?
An index is a database feature that helps improve the speed and efficiency of queries made against a database table. They help when searching through large, unordered data sets and give the database search engine a quick way to sort and find specific data. Indexes can be created using one or more columns of a database table, providing the basis for both rapid random lookups and efficient access to ordered records.How do they work?
A table index is very similar in practice to the index of a textbook. When there is a specific piece of information that you want to find, reading every page of that book to find what you are looking for can be very slow and inefficient. So, you would use the index at the back of the book to find exactly which page contains the information you need. This is the same concept for a database table index. They create a special type of lookup table in the background that the database engine can use to retrieve the data faster than looking through each individual row for every search.When to use an Index?
Indexes are the most beneficial in the following scenario(s):- You have a specific query that you want to ensure is as performant as possible
-
The query uses simple operators in one or more conditions
- Yes: Where user region = Canada
- No: Where user ID is even, or user region is empty
- The table has 10,000 records or more
-
The table is not frequently written to or updated
- This is because when a table is indexed and frequently written to, the performance of inserting new data can suffer because the index has to be updated at the same time. You can index a table that has frequent writes, but use caution.
How do I apply an index properly?
It’s important to construct your index based on the query being performed that you are trying to address. We will use the an example scenario to explain an approach to indexing. All scenarios were built and performed on a Launch plan instance with no additional load or processing. Your results may vary based on other factors related to your specific instance or the plan you are on.Example Table: 515,195 records, with the following schema
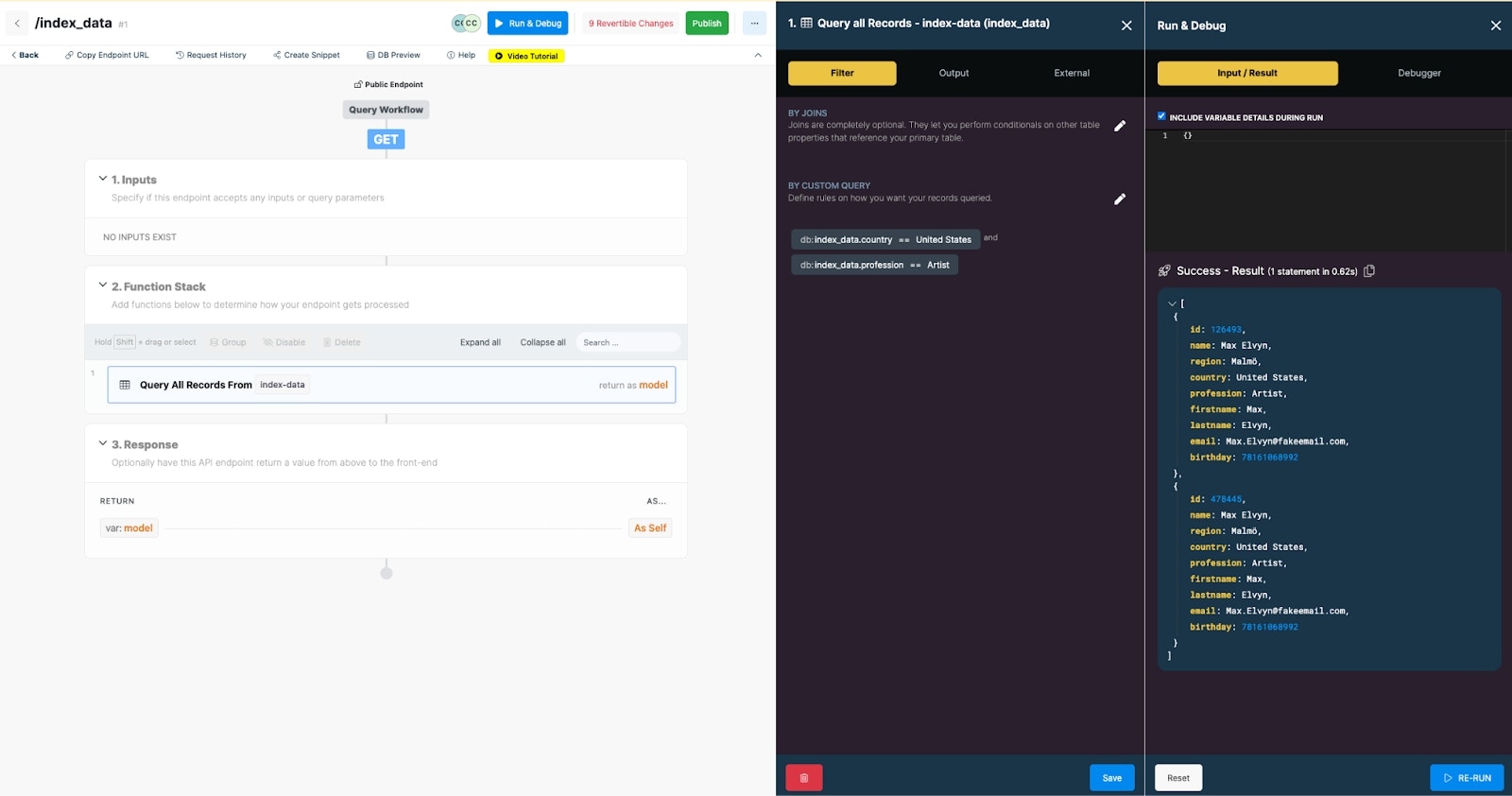
Example Query: Find all users in a specific country, with a specific profession
Example query with no indexing
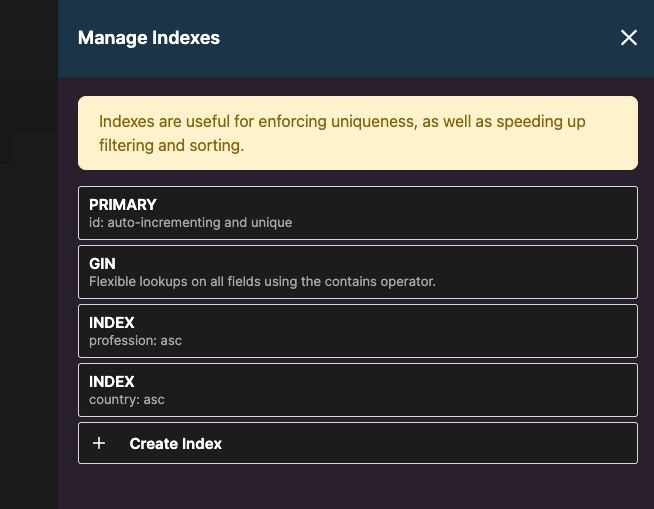
Indexes applied based on the sample query
Example query with indexing applied
When should I index a single field by itself vs multiple fields in the same index?
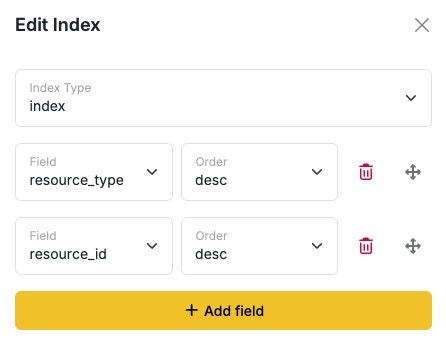
This is based on the hierarchy of the query being performed, and what makes the most sense in terms of your data set. It is also important to understand how multi-field indexes are executed. The order of fields in your index matters. When building a multi-field index, you want to start with the field that contains the **least **amount of unique values, moving forward to finishing with the field that has the most unique values. With a multi-field index, each ‘step’ (field) is essentially placed into a new bucket that the database knows it can use to potentially find matching data. Using an example of location data where we have acity, state, and country field, we know that country has the least unique values. This means that when we’re building our index, we’d add the country field first. Moving on from there, we would add our states, and then finally the cities, so when the database builds the index, it builds the most efficient bucketing possible.
In an adverse example, consider an index on a timestamp field. Timestamps in Xano use milliseconds, which obviously means that these values will almost be unique for every single record. If we built a multi-field index that started with this timestamp field, we are creating that many buckets right away before trying to look for less specific data, which means that the query becomes extremely inefficient.
It is also important to note that if you have multiple fields defined in a single index, but are not using both of those fields in your query, the index will not provide any benefit to the performance of that query. Indexes are only useful if you are indexing based on the queries you are making, and the hierarchy of your query makes sense.
You can use a field in a double-field index as well as a single-field index, but it is important to consider the storage requirement for each index you create. In addition, it is possible to ‘trap’ yourself into a situation where you have too many indexes, and it becomes more difficult to determine what is helping and what is not.
Example Query: Find all users who are part of a specific subset of artists
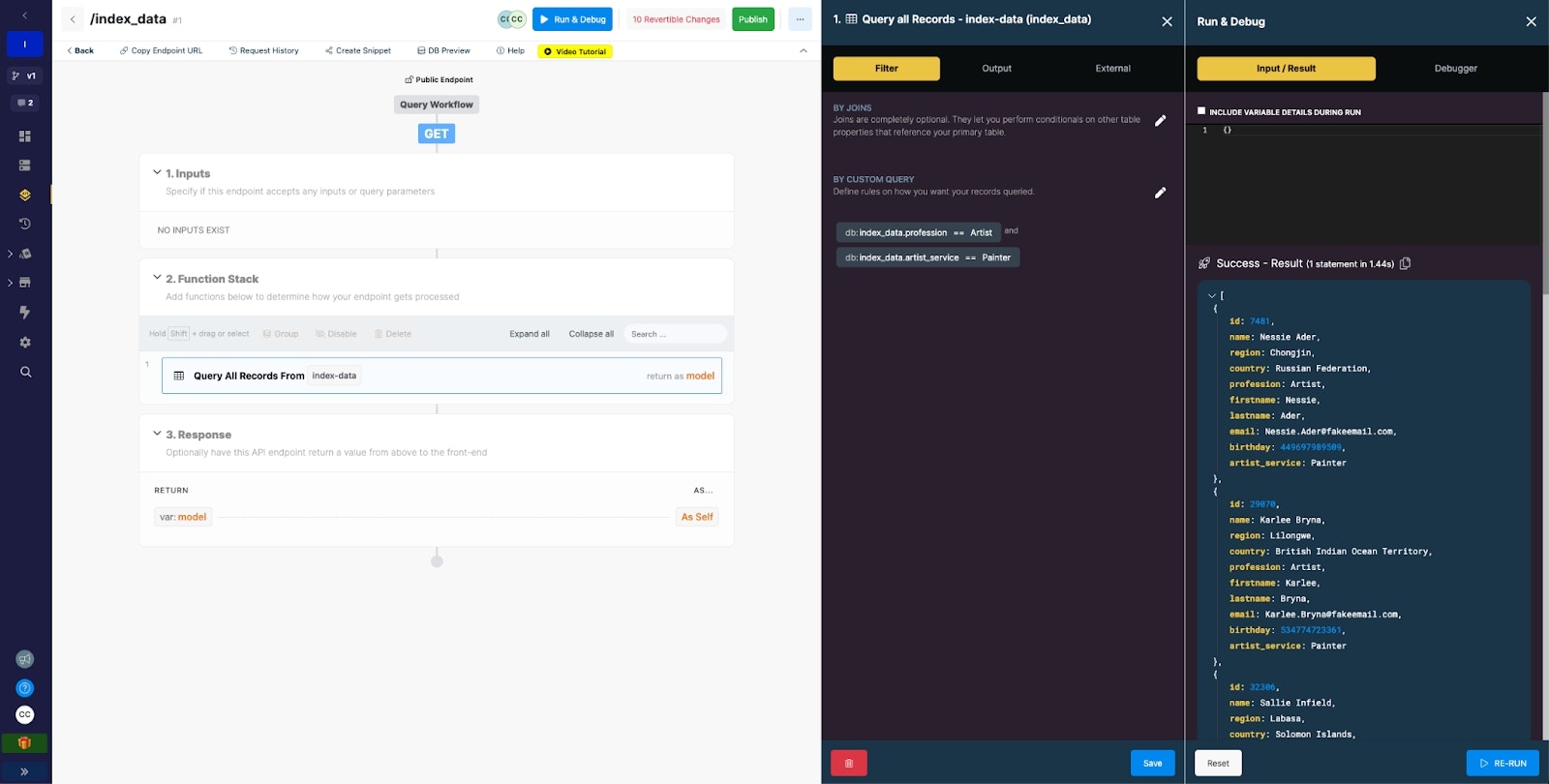
Example query with no indexing
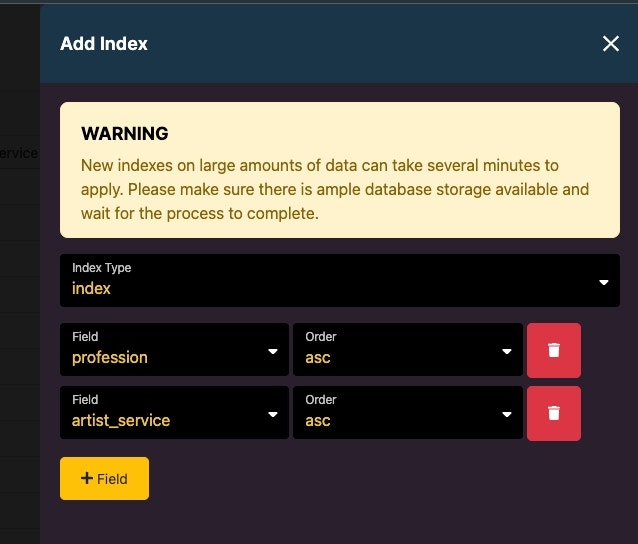
Applying the index for the example query
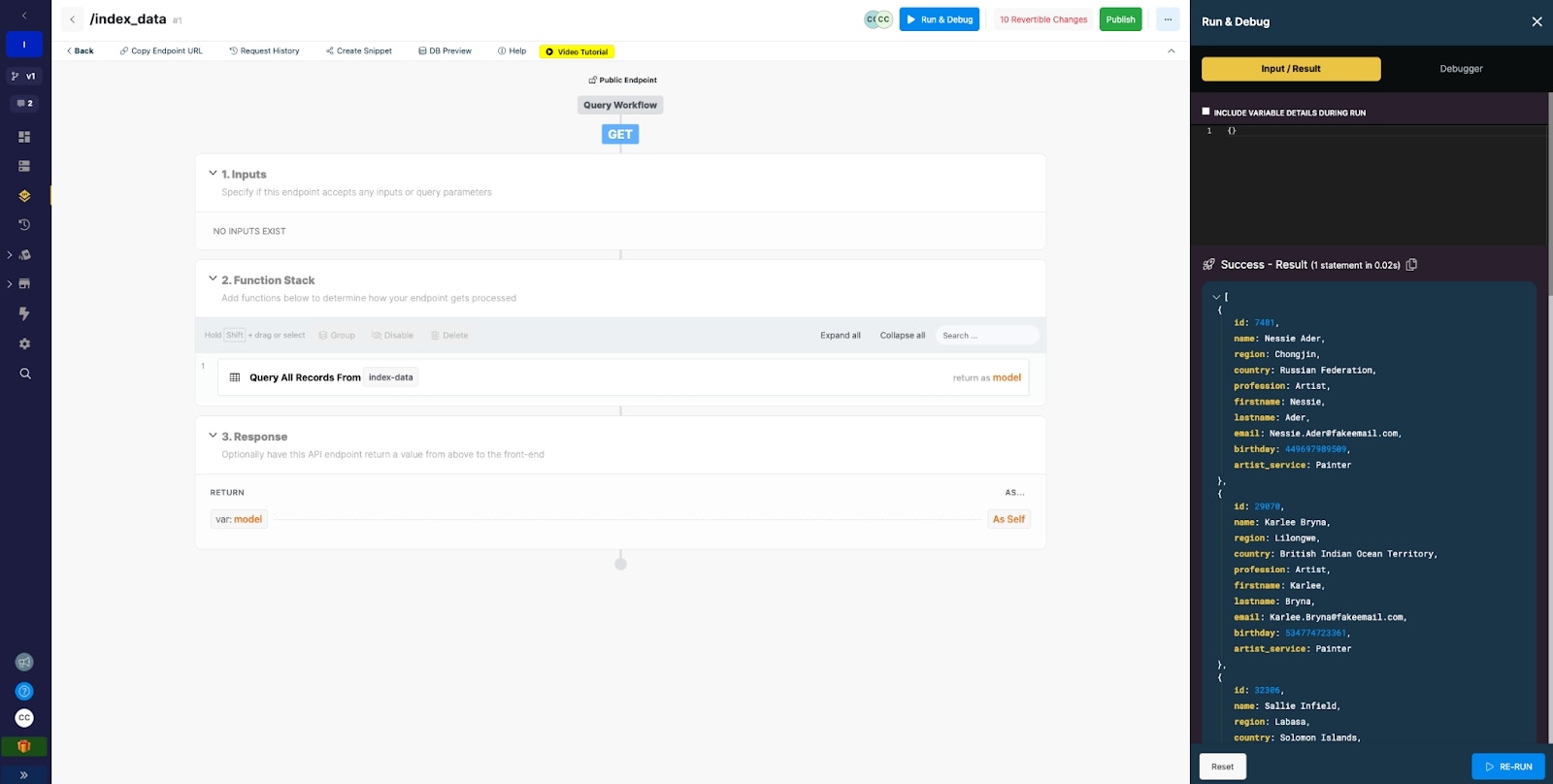
Example query results with indexing applied
Using the GIN Index to search complex data types
The GIN index is used specifically when searching through more complex data types, such as objects and arrays, as these fields can not be indexed using the methods described previously. This index is automatically applied to all of your database tables; you do not need to add or maintain this. Let’s say, as an example, we have a list field called my_list, and we want to find all records that contain a value of special inside of my_list. To use the GIN index in this query, we first need to create a variable with the following structure: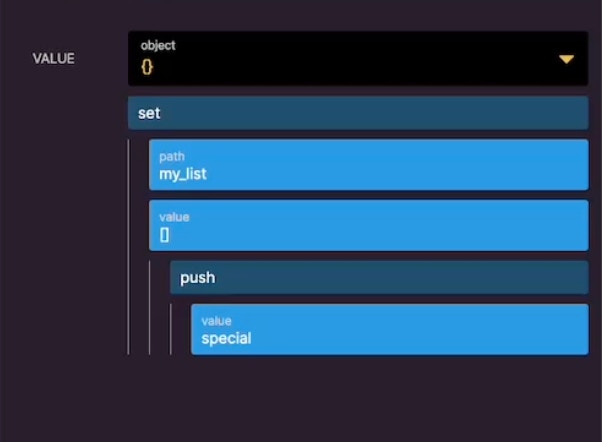
Constructing the variable to be used in our query
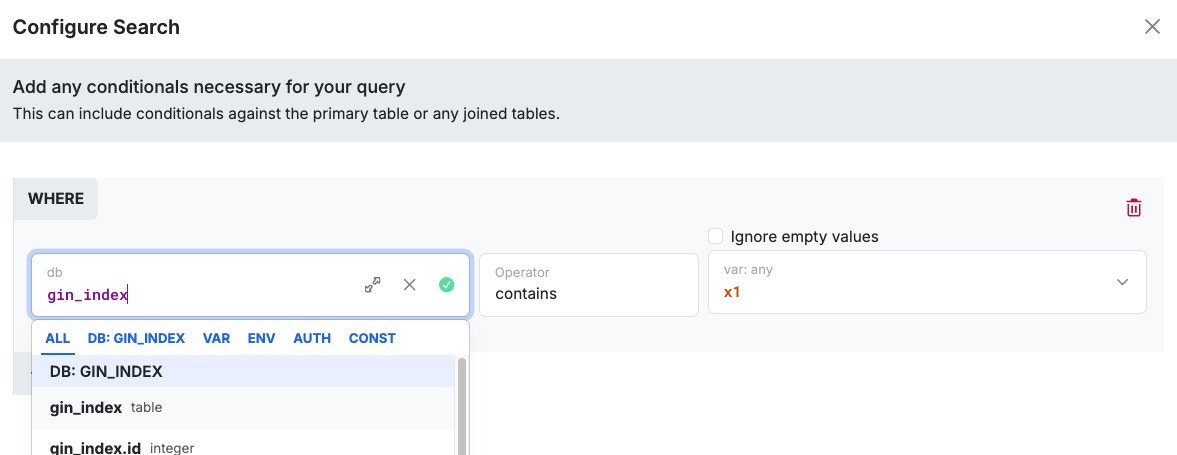
An example of a GIN index query
How to Apply an Index in the Database View
In the database view, click on the table that you want to index. Choose “Indexes” from the top bar.
Types of Indexes
- Primary
- Automatically applied and maintained
- Indexes the primary key (ID) of each record and enforces uniqueness
- GIN
- Automatically applied and maintained
- Most suitable for complex data types (JSON, lists, objects) and full-text search
- Index
- The most common index type
- Used when indexing for standard queries
- Unique
- A special type of index to enforce unique values in a column’
- Spatial
- A special type of index designed to optimize queries involving spatial data, such as geography fields.
- Search
- A special type of index to be used in conjunction with Xano fuzzy search
- Vector
- A unique indexing type used for working with the Vector field type.
- Indexing should always be used on vector columns, regardless of the amount of records.
- L2 Distance - Measures the Euclidean distance between vectors
- L1 Distance - Measures the taxicab distance between vectors.
- Inner product - Measures dissimilarity based solely on amplitude (recommended for OpenAI and other normalized vectors)
- Cosine Distance - Measures dissimilarity between vectors, considering their length and amplitude
When should you not use an index?
- Do not use an index on a table containing only a few records. They are most valuable when your record count approaches >5,000 records.
- Indexes should not be used on fields that have or will have a high number of null values, because that essentially means there is nothing to index on.
- You can not apply a normal index to an array or object field, so keep that in mind when designing your database structure. You can use the automatically maintained GIN index, detailed later on this page.
- If your field / column names are frequently changing, you should not index that field.
- If a table is frequently used to add / edit data, it may be best practice to not index this table. While your query speeds can still benefit, they can also slow the performance of adding to or editing data on this table given the nature of creating an index behind the scenes.